
この記事を読むのに必要な時間は約 10 分です。
前回のトライツブログでは、B2B営業をDX(デジタルトランスフォーメーション)化するための第一歩として、今SFAに入力されているデータが不十分だと思えていても、まずはそれを分析することの有用性をご紹介しました。今あるデータを分析することで、現在のSFAの使い方をチェックするだけでなく、今後の営業活動の進め方のヒントを得られるからです。
しかし、SFAに入力されているデータをいざ分析しようとしても、データの大部分がテキスト形式で入力されているのでどう処理したらよいか分からない、ということがよくあります。普通の数字のデータであればExcelで難なくグラフを作ることができるけど、「テキストマイニングはやったことがない」「よく分からない」という人は結構多いのではないでしょうか。
そこで、SFAデータに含まれている大量のテキストデータを分析する方法を、簡単にご説明します。SFAのテキストマイニングでどんなことが可能なのか、どうすればSFAのテキストデータを分析できるのか、一緒に見てみましょう。
そもそもテキストマイニングとは?
テキストマイニングとは、データの中に含まれている単語を抽出し、それらの単語が出現する頻度や傾向を分析するというものです。これをSFAデータで使えば、受注する商談と失注/停滞する商談とで、顧客との会話の中に出てくる単語や、上司に報告する文章の中に出てくる単語がどのように違っているか、といったことが分かります。
ある会社のSFAデータを分析したところ、自分たちから仕掛けて始まった商談と、顧客からの引合で始まった商談とで、受注との関連性の高いキーワードが異なっていた、ということがありました。これはつまり、そこの会社の営業マネージャーにとって、商談のスタートの仕方に応じて、部下の商談をチェックする観点が異なるということ。そして、これをもとにSFAの入力項目を商談のスタートの仕方に合わせて見直すことができれば、営業担当者自らがそのキーワードを意識して商談するようにもなるでしょう。このように、テキストマイニングを活用することで、営業マネージャーの仕事の仕方やSFAのさらなる活用方法についてのヒントを得られることがあるのです。
無料ツールで誰でも手軽にテキストマイニングが可能に
高価な分析ツールを購入しなければテキストマイニングをできなかったのも今は昔。立命館大学の樋口耕一氏によって開発・配付されている「KH Coder」をはじめ、簡単に操作ができる無償ソフトが数多く出てきています。その中でもKH Coderは、学術論文でも使われるほどしっかりとしているツールなので、私もよく使っています。ご興味がある方はダウンロードして使ってみてください。
それでは、このKH Coderをベースにして、テキストマイニングを実施するための4ステップを以下ご紹介します。
ステップ1.データを準備する
まずはSFAのデータをExcelまたはCSVの形式でダウンロードし、分析の目的に応じて下準備をする必要があります。SFAのデータを大まかに分けると、日々の活動報告データとそれが帰属する商談データ、チャットなどのコメントデータに分かれます。先ほどご紹介した例のように「受注する商談のデータに出てくる単語の傾向を知りたい」という場合は、活動報告データごとに入力されているテキストデータを、商談ごとにまとめるという処理が必要になります。
「何を分析したいのか」「その分析のために必要なデータの単位は、商談なのか訪問(活動報告)なのか」を考え、それに合わせてデータを準備するのが最初のステップです。
ステップ2.単語を抽出する
テキストデータを分析するとき、大量の文字列を単語ごとに区切ってカウントするという作業が必要になります。例えばSFAデータの中に「買う」「買いに」「買って」「買おう」「買えば」という言葉が1回ずつ出たときに、これらを別の単語とするのではなく「買う」という単語が5回出たと処理しなければなりません。一見すると気が遠くなるほど面倒くさそうですが、テキストマイニングのツールの中には辞書ファイルが内蔵されており、ステップ1で準備したデータを読み取った後に自動で単語を抽出してくれます。このステップはツールにお任せできますので、ご安心ください。
ステップ3.類似語をまとめる
単語としては別物でも、意味合いが似ている言葉は1つにまとめる方が分析上便利ですし、意味があります。この意味合いは似ているが別になっている単語を1つにまとめることを「コーディング」と呼びます。
SFAデータを分析する際は、BANTC(予算、決裁者、課題、時期、競合)に関する情報と受注や商談の進捗状況を掛け合わせることが多いので、「課題」「問題」「ニーズ」「要望」などの単語を「課題」にまとめるというように、BANTCを中心にコーディングすることがお勧めです。その後、実際の入力データを見ながら、商談進捗のカギとなりそうな単語とその類似語をコーディングしていきます。
ステップ4.分析する
ステップ3までの処理をしたら、ようやくテキストデータの分析が可能になります。この分析も最近のテキストマイニングツールを使えば、ボタン1つでグラフの作図まで全部自動でやってくれますので、試してみるに当たってのハードルはかなり低いはずです。
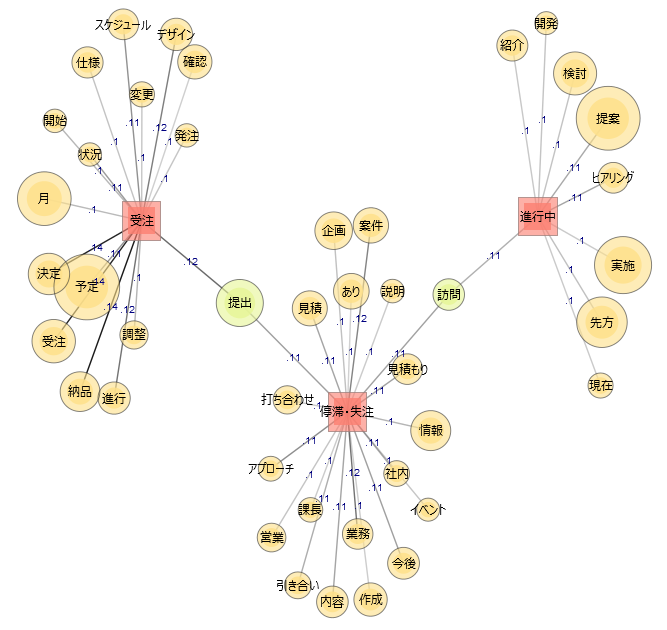
上のグラフはSFAデータのテキスト入力項目と、商談の結果(受注、停滞・失注、進行中)の関係性をグラフ化したものです。丸が大きい単語ほど頻繁に登場しており、線が濃いほど関連性が強いことを表しています。このグラフは、単語同士が一緒に発生する度合を図解しているため「共起ネットワーク」と呼びます。
グラフを見ると、左上の受注している商談では「納品」や「スケジュール」「進行」「仕様」「デザイン」など、商品の具体的な内容を顧客とやり取りしている様子が想像できます。その一方で、中央下の停滞・失注している商談では「情報」「アプローチ」など商談初期に出てくるであろう単語や、「企画」「イベント」「説明」といった単語が出ており、商談を仕掛けてその内容を顧客に理解してもらうところで手間取っているであろう様子が見えてきます。
このグラフから「商品の仕様やスケジュールなどを顧客と具体的に詰めることが受注に寄与する」という傾向が見て取れますので、商談の早いタイミングから受注後の進め方を顧客と話すようにする、そのためのツールを用意する、といった工夫が考えられそうです。また、これまで以上に「提案の内容や価値が顧客に分かりやすいか」という観点で、提案書をチェックする必要がありそうだということも分かります。
ステップ3までの作業を行ったデータはExcelやCSVなどの形式でダウンロードできます。レコード(この場合は商談)ごとに指定した単語やコードが含まれていればフラグ(数字の1)が振られていますので、これを他のデータと組み合わせてより複雑な分析をすることも可能です。テキストマイニングソフトは、もちろん単体での分析もできますが、他の分析用ソフトウェアでテキストデータを分析できるようにするための前処理のツールとしても使えるのです。
営業現場と一緒にアウトプットの解釈を楽しもう!
このように、一見取っ付きにくそうなテキストマイニングですが、やっていることはとてもシンプルですし、たいがいの面倒くさい処理はツールで自動化できます。データの下準備とコーディングさえできていれば、膨大なテキストデータでも簡単に分析することが可能なのです。
ただ、分析結果を解釈し意味を見出すという大事な仕事は、分析者に残されています。その時に注意していただきたいのが、マイニング(金属の採掘)という言葉のとおり、出てくるアウトプットのうち本当に価値のある情報(金塊)はほんの一握りで、残りはただの石ころでしかないことが往々にしてあるということです。そのため、「きっとすごいアウトプットが出てくるはず!」と過度に期待をするのではなく、「1つのグラフから面白いアイデアが2~3つ見つかれば儲けもの」ぐらいの感覚でアウトプットを解釈するのが良いと思います。
そして、出てきたアウトプットはぜひ営業現場にフィードバックしてください。「あんな適当なデータから、ちゃんと傾向が出るんですね!」と面白がってもらえますし、退屈な作業になりがちなSFAに商談情報を入力することの意味や価値を再認識してくれることでしょう。また、先ほどのようなグラフを一緒に見ながら「何が言えるか」をブレインストーミングするのも、けっこう楽しいものです。
誰でも簡単にテキストマイニングができるようになってきた
駆け足でSFAデータのテキストマイニングの仕方についてご紹介しましたが、いかがでしたでしょうか。
「難しそうだと思っていたけど、意外とシンプルなんだな」「自分でもできるかも」と思っていただければ幸いです。データの下準備や分析手法の指定の仕方など、統計解析の素養がある方が望ましくはあるのですが、やっていることはそこまで複雑ではないのです。
トライツコンサルティングではテキストデータも含めたSFAデータ分析をサポートしています。「SFAにデータは貯まってきているけど、どうやって分析したら良いか分からない」「テキストデータの分析は不慣れだ」という方はぜひご相談ください。

